

Debugging mutable subresources: a detective story
The bizarre case of Signed Exchanges: how frequent deployments increased the error rate and revealed hidden cache poisoning (part 5 of 8)


Prefetching errors eliminate 99% of the benefits of using Signed Exchanges (SXG). This is why it's critical to resolve these errors. While you learned how to handle two common errors in the previous post, this article will address a more complex error that shares some similarities with those issues.
As I write, there is no official or unofficial documentation on the issue described in this post.
If you don’t know what SXG is, or need a refresher, please start from the beginning.
This one was fun
The error I observed was different from the previous two. This time:
all subresource types were affected,
subresources were targeted randomly, but not all at once,
if a given subresource was affected, the error occurred for some time (a day for example) and then disappeared (or moved to another subresource).
To make things even more interesting, the error rate was proportional to our development activity. Deploying more often caused more errors to occur. The obvious solution was to fire developers and stop working on the app!
Since my role as a programmer was at risk, I had to find another way to fix it. I found a workaround pretty quickly, but it took me a long time to understand the cause. I demonstrate my thought process below.
Comparing fresh and cached versions
First, I fetched the problematic, SXG-wrapped page with the dump-signedexchange tool (you have to remember to selectively or globally deactivate Cloudflare bot protection when using it):
$ dump-signedexchange -uri https://www.planujemywesele.pl/bad-page
...
response:
status: 200
headers:
...
Link: <https://www.planujemywesele.pl/sub.css>;rel=preload;as=style,<https://www.planujemywesele.pl/sub.css>;rel=allowed-alt-sxg;header-integrity="sha256-/6M5qdrjQUl+dCdWtFqN50BmBvAHZ+sJxiLaoraBO2s="
signature: ...
header integrity: ...I removed almost everything from the output and made the important part bold: the subresource header integrity hash.
Then I used the same tool to fetch the problematic SXG-wrapped subresource:
$ dump-signedexchange -uri https://www.planujemywesele.pl/sub.css
...
header integrity: sha256-/6M5qdrjQUl+dCdWtFqN50BmBvAHZ+sJxiLaoraBO2s=The integrity hash of the subresource is the same in the document and in the subresource itself. That’s the way it should work.
Now, let’s see what Google cached. We can use the same tool to examine it:
$ dump-signedexchange -uri https://www-planujemywesele-pl.webpkgcache.com/doc/-/s/www.planujemywesele.pl/bad-page
...
response:
status: 200
headers:
...
Cf-Ray: 8f61c1c4a09ce802-ORD
Link: <https://www.planujemywesele.pl/sub.css>;rel=preload;as=style,<https://www.planujemywesele.pl/sub.css>;rel=allowed-alt-sxg;header-integrity="sha256-gxoxVoIaE8MKl8tf283F3FKVF8NwrLqz2jMT/vwyO9c="
signature: ...
header integrity: ...The header-integrity hash is different!
Let’s examine the HTTP response carrying Signed Exchange payload using curl:
$ curl -iH "Accept: application/signed-exchange;v=b3" https://www-planujemywesele-pl.webpkgcache.com/doc/-/s/www.planujemywesele.pl/bad-page
...
link: <https://www-planujemywesele-pl.webpkgcache.com/sub/gxoxVoIaE8MK/s/www.planujemywesele.pl/sub.css>;rel="alternate";type="application/signed-exchange;v=b3";anchor="https://www.planujemywesele.pl/sub.css"
...The Link header points to a URL to a cached version of SXG-wrapped subresource, so that the browser can prefetch it. This URL is constructed from the URL and a part of the integrity hash (in bold).
When we try to fetch it using curl:
$ curl -iH "Accept: application/signed-exchange;v=b3" https://www-planujemywesele-pl.webpkgcache.com/sub/gxoxVoIaE8MK/s/www.planujemywesele.pl/sub.css
...
location: https://www.planujemywesele.pl/sub.css
content-type: text/html; charset=UTF-8
...
<HTML><HEAD>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>Redirecting</TITLE>
<META HTTP-EQUIV="refresh" content="0; url=https://www.planujemywesele.pl/sub.css">
</HEAD>
<BODY onLoad="location.replace('https://www.planujemywesele.pl/sub.css'+document.location.hash)">The fallback page will be returned telling us, that the entry doesn’t exist in the Google SXG cache.
Now, it is very clear that the SXG-wrapped page cached by Google is different because it links to another subresource. And this subresource can’t be found in the Google SXG cache. This is a cause for prefetching failure and CORS error.
Why did Google cache a different page?
To get Google’s perspective, we can use Google Search Console. It contains a URL inspection tool that has a Live test feature. It lets you use Googlebot to fetch any URL on your website and examine the results.
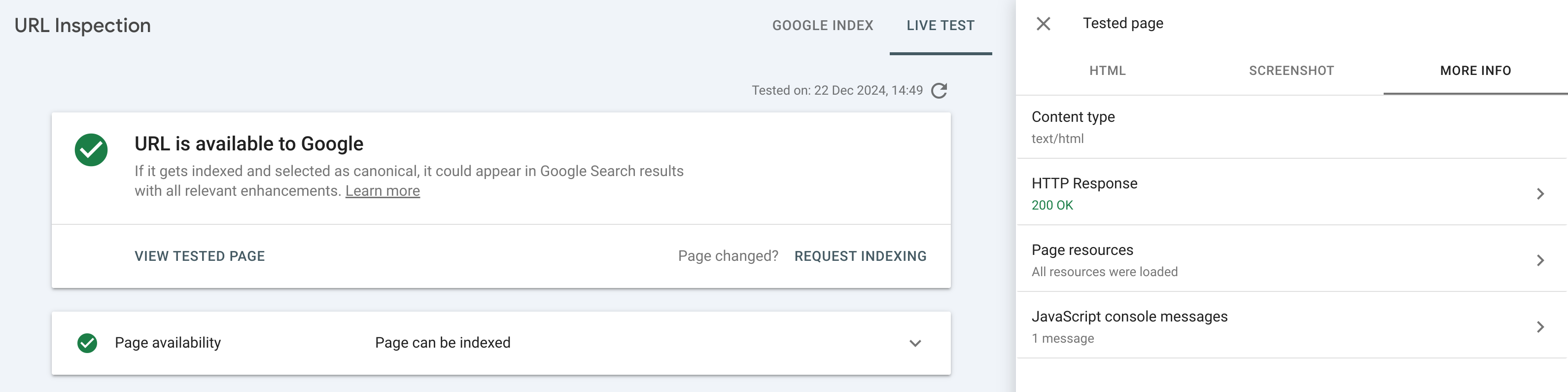
When you open the More info tab and click the HTTP Response, you will see the HTTP headers. Here they are, redacted to include only interesting bits:
HTTP/1.1 200 OK
...
cf-ray: 8f6092f8e08e2231-ORD
link: <https://www.planujemywesele.pl/sub.css>;rel=preload;as=style,<https://www.planujemywesele.pl/sub.css>;rel=allowed-alt-sxg;header-integrity="sha256-gxoxVoIaE8MKl8tf283F3FKVF8NwrLqz2jMT/vwyO9c="
...The header-integrity hash is the same as in the Google SXG cache. So we have the answer to the most recent question: Google cached what it saw which is different from what we see.
Why does Google see the world differently than we do?
My first thought was that Cloudflare treats Googlebot differently than others. I even formulated an entire theory based on this assumption. But it was a dead end.
Cloudflare has data centers all around the world. What if two different data centers return different pages? Particularly, what if the data center close to Google returns a different page than the data center near me? To verify it, the first step is to find the data center used for Googlebot traffic.
Which Cloudflare data center handles Googlebot traffic?
In the SXG responses intended for Googlebot, Cloudflare includes a Cf-Ray header. This header contains an identifier of the Cloudflare data center used to handle the request.
My suspicion about Cloudflare treating Googlebot differently was correct because this header is served only for this bot.
I tried to impersonate Googlebot by setting the User-Agent request header, but the Cf-Ray header was not added as a result. They probably use a more reliable, IP-based detection of Googlebot.
In the responses you saw above, the data center is identified as ORD. Cloudflare has a status page listing all data centers and their geographical locations:

It seems Cloudflare uses airport codes for data center identifiers. As you can see, ORD is Chicago.
It means Google accessed my website using the Cloudflare data center located in Chicago, at least for requests I examined, and at the moment I did it. It may change in the future, but it’s quite consistent for now.
Sitting where Google sits
Now, that I knew the data center, I tunneled to Chicago using a VPN:
$ mullvad relay set location us-chi-wg-101
Relay constraints updated
$ mullvad reconnect -w
Connecting
Relay: us-chi-wg-101
Features: LAN Sharing, Quantum Resistance
Visible location: USA, Chicago, IL
Connected
Relay: us-chi-wg-101
Features: LAN Sharing, Quantum Resistance
Visible location: USA, Chicago, ILFinally, I checked if Cloudflare routed me to the correct data center. The Cf-Ray header for non-SXG responses is accessible to anybody, not only Googlebot:
$ curl -si https://www.planujemywesele.pl/ | grep cf-ray
cf-ray: 8f6229558f9710c2-ORDOk, I was using the same data center as Googlebot. Now, I fetched the SXG:
$ dump-signedexchange -uri https://www.planujemywesele.pl/bad-page
...
response:
status: 200
headers:
...
Link: <https://www.planujemywesele.pl/sub.css>;rel=preload;as=style,<https://www.planujemywesele.pl/sub.css>;rel=allowed-alt-sxg;header-integrity="sha256-gxoxVoIaE8MKl8tf283F3FKVF8NwrLqz2jMT/vwyO9c="
signature: ...
header integrity: ...The header-integrity hash is the same as in the cached version and as seen by Googlebot, but different from what I saw when accessing the website without VPN.
This proves that the Chicago data center serves a different version of a page than the data center close to me.
Which version of the page is correct?
I fetched the subresource while using the Chicago data center via VPN:
$ dump-signedexchange -uri https://www.planujemywesele.pl/sub.css
...
header integrity: sha256-/6M5qdrjQUl+dCdWtFqN50BmBvAHZ+sJxiLaoraBO2s=The header integrity is the same as when I fetched it without VPN, from my original data center.
Given the following facts:
My non-VPN data center returns a page linking to a subresource with integrity hash X.
Chicago data center returns a page linking to a subresource with integrity hash Y.
Both data centers return a subresource with integrity hash X.
It becomes clear the Chicago data center returned a broken page.
What’s wrong with Chicago?
Is the Chicago data center special? It seemed so because I was getting consistently good results when switching to different data centers using a VPN. Only Chicago returned an invalid page.
I heard that in Chicago, they don’t put ketchup on their hot dogs. That could be the reason, but I kept searching for other explanations.
The subresources causing troubles were most often shared between different pages. I tested many of those pages from Chicago with a VPN. Each page linked to a subresource with an invalid integrity hash.
Is the cache entry for a page broken?
Each Cloudflare data center has its own cache. Maybe the cache was to blame? What if for some reason, the Chicago data center cache contains broken entries for the pages I tested?
This led me to test a page that I was sure wasn’t accessed before and, therefore missing from the cache. To my surprise, this fresh page still referenced subresources with invalid integrity hashes!
Is the cache entry for a subresource broken?
No matter which data center I used to obtain the subresource, it gave me the same data. So the subresource was fine.
Just to be sure I purged the page and the subresource from the Cloudflare cache and performed the test again. The result was the same - I got a page linking to a subresource with an invalid integrity hash.
It seemed the data center had remembered the wrong integrity hash and used it to generate SXG responses.
Remembering things is the role of a cache. But I cleared it! It didn’t make any sense, unless…
There is another, hidden cache!
When I think about it now, it’s obvious. Cloudflare uses a special-purpose cache for integrity hashes to minimize latency when generating SXG responses. As with Automated Signed Exchanges (ASX) instances, this cache is local to every data center.
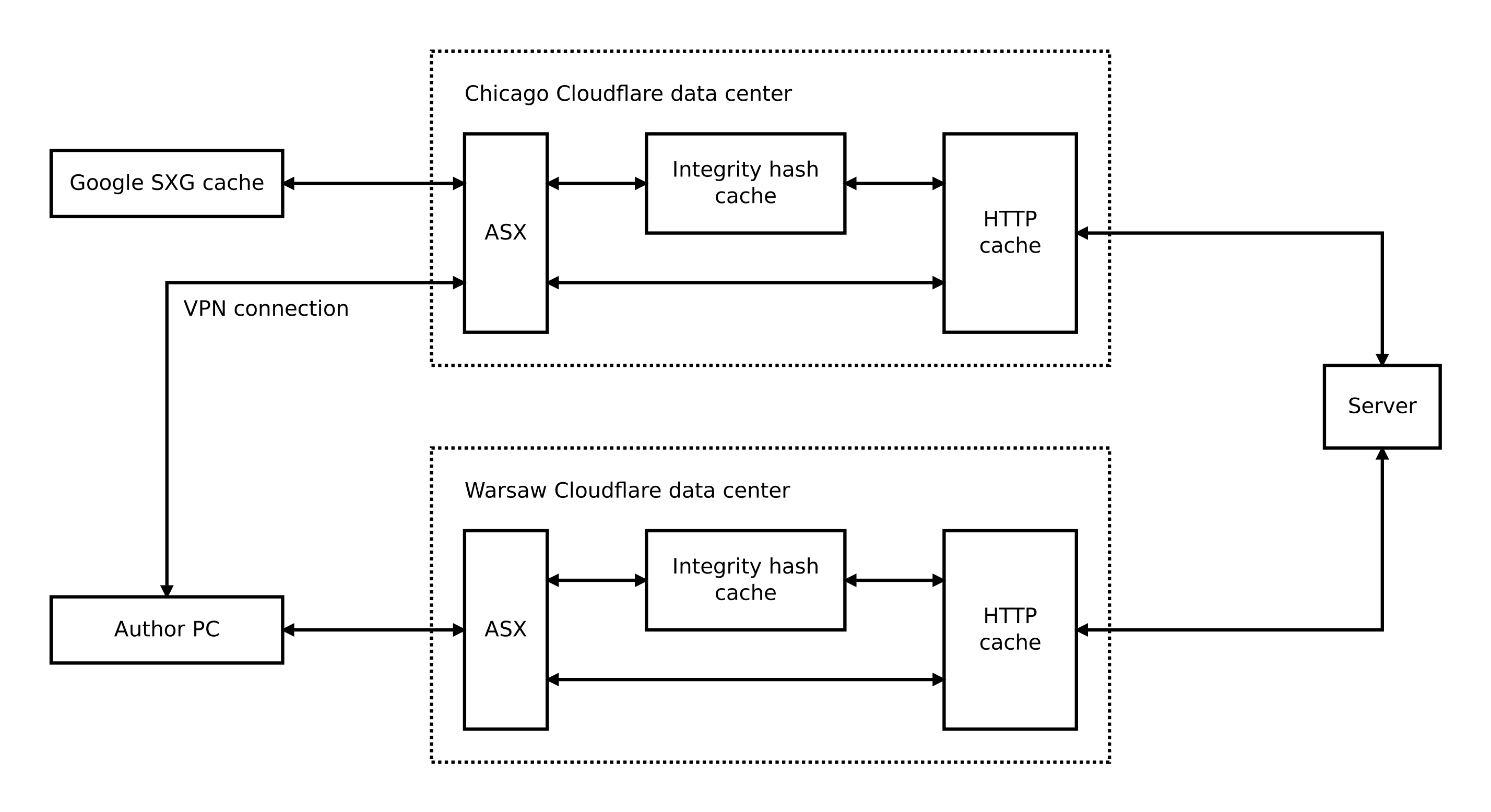
I validated this hypothesis by putting logging workers before subresources linked by the page. This way every request was logged, because workers are invoked every time, even for cached entries.
Then I requested SXG of the page and observed logs. The subresources were accessed only once per data center. Further requests for SXG didn’t result in any logs, even after purging the cache.
The hidden cache I discovered is not mentioned anywhere in the documentation. It can’t be purged just like the normal Cloudflare cache. It’s an opaque black box.
Sometimes, this black box contains invalid integrity hashes leading to populating the Google SXG cache with invalid pages and breaking the SXG experience for the end users. I would say the hidden ASX cache seems poisoned.
Why is the ASX cache poisoned?
I believe it’s caused by a delayed subresource mutation.
When a client requests the SXG page for the first time, ASX may retrieve the subresource and store its integrity hash in the local ASX cache. Later, the subresource mutates, but this fact remains hidden as long as the original version remains in the Cloudflare cache. The issue starts to manifest after it is evicted from the Cloudflare cache: the page links to a subresource that is no longer there.
The Google SXG cache obscures the issue further because it stores both versions of the subresource. However, user-visible issues can arise in two scenarios:
When the Google SXG cache evicts the original version before it expires.
When technical problems (such as network issues) prevent the Google SXG cache from successfully storing the original version during the initial data collection.
In either case, this results in the Google SXG cache only having the mutated version of the subresource, while the original version becomes unavailable. As the page refers to the original version it causes prefetching errors. And because the ASX cache is poisoned, the error will stay there no matter how often the Google SXG cache tries to refresh the entry.
I could not validate the two scenarios described above because they depend on hard-to-control conditions. Therefore it should be treated as a hypothesis. However, I successfully demonstrated ASX cache poisoning by artificially simulating technical issues while Google's SXG cache performed its initial fetch of the subresource.
How to fix ASX cache poisoning?
Now that I knew the cause—delayed subresource mutation—I could solve the problem by eliminating this mutation. By comparing various responses I was able to find the source of the mutation.
It was the Etag header.
Etags and deployments
The Etag HTTP header is an optional identifier sent along with the response. It should stay the same unless the response content changes. When the browser fetches the URL again, it includes the Etag value of the locally cached response. The server compares the received value with the current value. If they differ, it sends the response as usual. But if they are the same, it returns an empty response with 304 Not Modified status, saving bandwidth.
Etags may be used for every response type, but in the case of SXG the most important are static assets, so let’s focus on those.
This is how etags for static assets are generated by various components of my stack:
Nginx generates etag for a given asset using its size and modification time.
Ruby on Rails app leaves it to the web server (it this case nginx).
If your deployment method (like mine) writes the static assets to disk even if they didn’t change, then their modification time will be updated as well. In effect, nginx and Next.js will generate new etags even if the files remain the same.
I suppose other web servers and framworks behave the same.
It will cause some clients to download assets again. It’s a minor issue because assets are typically cached for a long time and etags are not needed until the cache expires.
Etags impact on SXG
However, the Etag header is included in the generated SXG subresource. If the etag changes, the subresource mutates. And given some conditions are met it leads to SXG prefetching errors.
In my case, the more often I deployed, the more often the subresource mutated. This was the reason why the errors intensified during increased development activity!
How to make etags and SXG work together?
It may be a good idea to ensure the modification times of your assets stay the same unless actually modified. I can’t explain how to achieve it in detail because it depends on the deployment method. And sometimes it may be non-trivial or even impossible to achieve.
Therefore, I suggest an alternative approach. Do not send the Etag header in responses for static assets. If you use a 1-year expiration date as I recommend, it's not a big deal anyway.
For nginx, you can set it globally with the following directive in the HTTP context, preferably in the nginx.conf file:
etag off; # Disable etag generation for static assetsNext.js allows disabling etags entirely. I don’t like this approach, because it also disables it for HTML responses. Instead, it can be done using nginx again, by removing the Etag header from the responses for static assets only.
I use the following nginx configuration snippet in locations containing static files:
location ~* \.(?:css|js|gif|png|jpeg|jpg|ico|ttf|woff|woff2|svg)$ {
# Clear etags set by Next.js as they vary between deployments
# even if the assets remain the same. This may leads to SXG failures.
# For more info see: https://blog.pawelpokrywka.com/p/debugging-complex-signed-exchanges-subresource-issue
more_clear_headers 'Etag';
# The rest of assets-related configuration, such as cache expiration
}Check the documentation of your web server and framework for hints on how to configure etags. For example, Apache offers an option to generate etags from file contents. This approach ensures immutability and eliminates the need to disable etags.
Alternatively, you can create a Cloudflare transform rule to remove the Etag header from all static assets. I have already explained how to create such a rule in the previous part. The only difference lies in step 6: instead of selecting Set static from the menu, select Remove and enter Etag in the Header name field.
As there is no way to purge the hidden ASX cache, remember to regenerate URLs to invalidate the cache (as described in the previous part) after implementing the changes.
Quick-fix for ASX cache poisoning
I found that bypassing the Cloudflare cache makes the ASX stop using the poisoned cache as long as the bypass is in place.
It means both caches share some logic. If Cloudflare went one step further and synchronized evictions between those caches, the issue described in this post would disappear instantly.
When I tried to disable the Cloudflare cache globally, the ASX stopped generating SXG-wrapped pages. If the cache is not used for too many assets, the SXG will break. It has to be disabled selectively.
To bypass the Cloudflare cache for a specific asset, go to the Cache Rules in the Caching section. Hit the Create rule button, fill out the form according to the template below changing the URL to match your asset, and click the Deploy button.
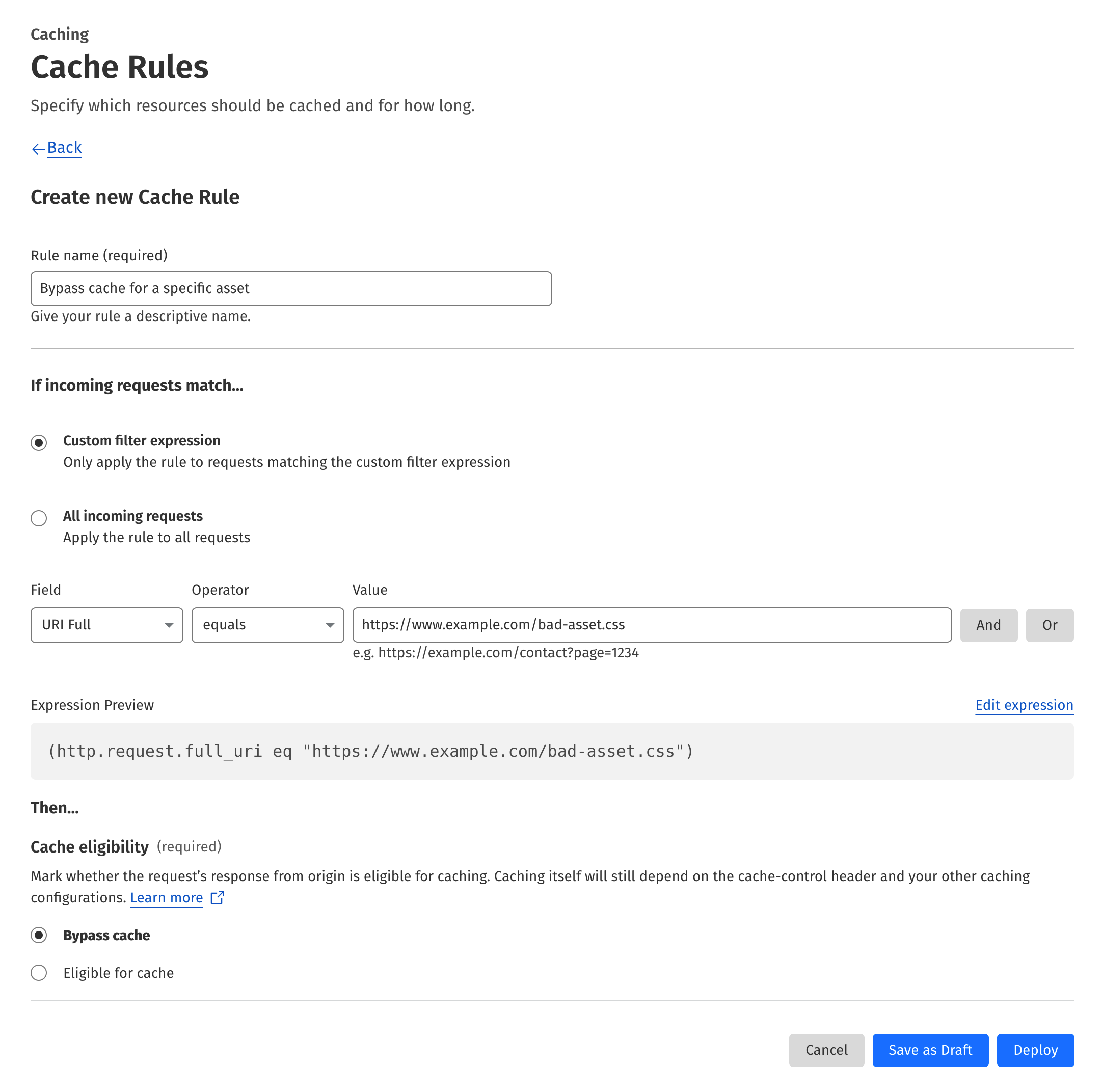
I don’t recommend bypassing the cache as it impacts the performance. But if you want to quickly check if the issue is related to ASX cache poisoning, you can use this technique.
That’s it!
I've demonstrated how to diagnose, understand, and fix this issue that's not documented anywhere. I hope you find it useful and perhaps learned something new about approaching unfamiliar problems.
While this concludes our discussion of mutable category errors, there are still a few other issues to address. I'll cover these remaining problems and their solutions in my next post.
Thank you for reading!