


Understanding CORS errors in Signed Exchanges
Learn debugging techniques and why the all-or-nothing principle makes these errors critical (part 3 of 8)

In the previous two parts, you learned how to enable Signed Exchanges (SXG) and let Google prefetch your site’s HTML and assets (or SXG subresources) on the search results page.
The effect: when the user follows the link to your website from Google, the page should load instantaneously from the browser cache. No need to wait for:
the page to become visible because HTML and CSS are already there,
the images—they are already downloaded,
the page to become interactive, because javascript starts executing without any delay.
Unfortunately, there are many scenarios in which it doesn’t work like that. If you met all the requirements I described in the first part of the series, HTML prefetching should work without issues. But prefetching subresources is tricky. It may cause trouble even if you strictly follow all the official recommendations.
Prefetching subresources is critical from the performance standpoint—much more important than HTML. Subresources are typically larger, so they take more time to download.
By reading this post you will learn how to diagnose SXG errors.
Disclaimer: This is not a CORS tutorial!
Although this post mentions CORS errors a lot, this is not a typical tutorial on configuring your website’s CORS policy. If you don’t know what is SXG and/or don’t use it, then please stop reading because you will waste your time. You will find a lot of valueable resources on the web. This is not the one you are looking for.
One bad apple spoils the whole barrel
When the browser prefetches the SXG page, it does it in two phases:
The browser downloads an SXG-wrapped HTTP response from the Google SXG cache. This response contains the HTML of your page (the main resource).
The HTTP response used to deliver the above contains a Link header. It includes a list of URLs of SXG-wrapped HTTP responses containing subresources. The browser downloads all of these URLs from the Google SXG cache.
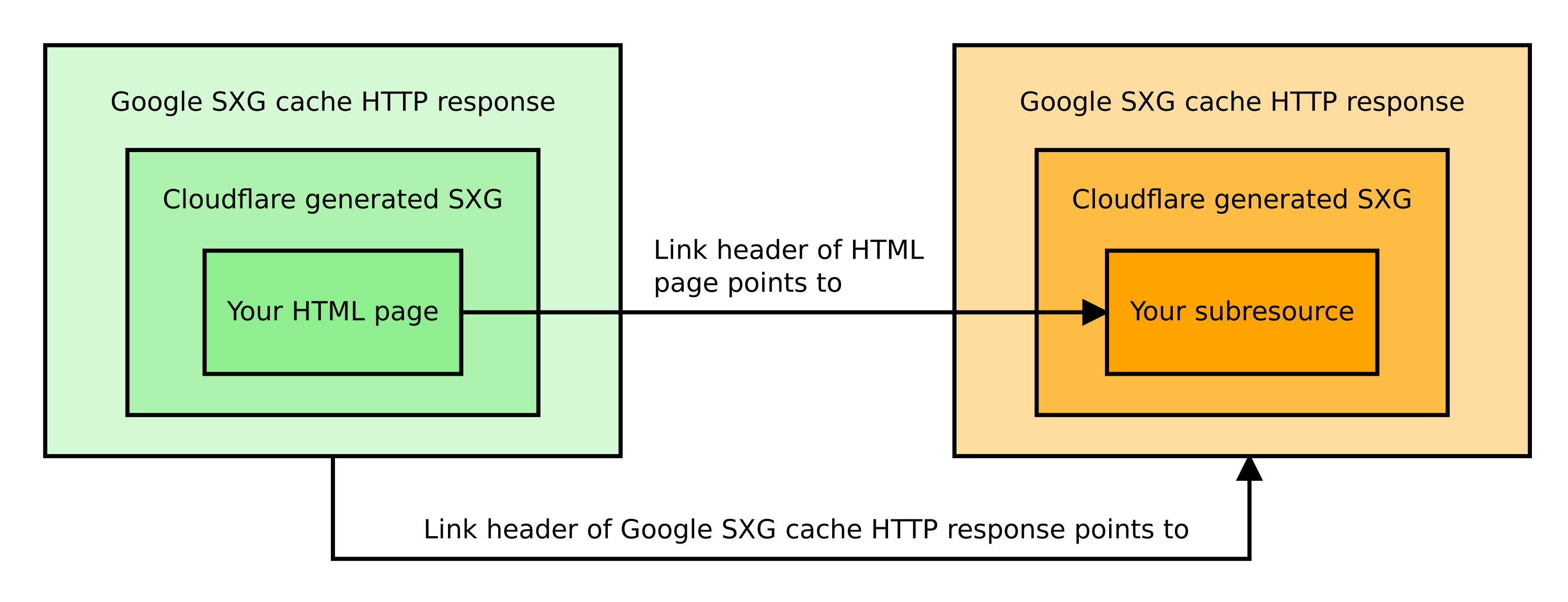
When the user decides to visit the page, the browser may use the downloaded subresources in the page rendering process. The important point is that it will use them only if all of them were successfully prefetched.
Let me reiterate this. Even if one of your subresources fails to prefetch for any reason, the browser will discard all of the already prefetched subresources and download them again during page rendering, slowing it down considerably. Most of your assets will be downloaded twice. What a waste of bandwidth!

This all-or-nothing principle is unforgiving in case of subresource loading errors. A little icon you tried to prefetch fails to load? Forget about 99% of the SXG speed benefits!1 That's why you should strive to eliminate all errors.
Why does it work that way?
SXG documents state it’s for privacy reasons:
“This is intended to prevent the referrer page from encoding a tracking ID into the set of subresources it prefetches.”
Let’s say the site uses 1282 subresources. Those subresources could be tiny, to not force the user to download too much data. Google could prefetch them selectively. For example the first subresource is prefetched and the rest is not for user A, the second and third are prefetched for user B, etc. It gives a total of 2128 combinations, allowing Google to encode 128 bits/16 bytes of data or about 150 ASCII characters.
Later, when visiting a website, it could use client-side or server-side logic to detect which subresources were prefetched and which were not. Using that knowledge, it could reconstruct (decode) the data passed from Google.
In effect, Google could pass any data to the website. It may be unique user identifier, search query, etc. This data could be used by the site for tracking.
The above method of passing data to the website it not the only one possible. If Google likes to, it could use URL anchor, Referrer header, or other more sophisticated ways.
Currently, Google chooses to protect user’s privacy, but we don’t know what the future may bring. What if SXG is used in other search engines that make different privacy choices? Or in entirely different context, where the collusion between reffering and target website is more probable? SXG’s authors wanted to prevent its misuse and didn’t want to create another way to track users.
SXG debugging
Classification of errors
There are a few places, where the issues with SXG may occur:
when the SXG is generated by Cloudflare,
when SXG is processed and put into Google SXG cache,
when the browser tries to prefetch SXG.
Another way of differentiating the errors is by determining what caused them. It might be:
the main document,
a subresource.
SXG Validator
You can use the SXG Validator browser extension described in the first part of the series. It doesn’t support subresources but will tell you if the main document was correctly generated by Cloudflare, processed, and put into the Google SXG cache. It will report cache ingestion errors as they occur.
However, if you follow the recommendations, you'll reach a point where the main document is fine and the SXG Validator becomes unnecessary.
Swiss-army knife for SXG debug
When debugging subresources, my favorite tool is the SXG prefetch page in Chrome Developer Tools, with the Network tab open.
It allows you to diagnose all the errors except those related to SXG generation by Cloudflare. Also, in my experience, it’s more reliable than SXG Validator which sometimes returns false negative results.
Using the SXG prefetch page
Upon visiting the page, you will be welcomed with a basic form.
Remember to open Chrome Dev Tools (by pressing the F12 key), go to the Network tab, and clear it by clicking the 🛇 icon or using the CTRL+L keyboard shortcut. Now enter the URL of the page you want to test and click the Submit button. The page will reload and prefetch the URL you provided.
Let’s submit the following URL:
https://www.planujemywesele.pl/muzyka-na-male-wesele/poznanAssuming the page is not yet present in the Google SXG cache, this will result in 3 HTTP requests:

The first two are related to the SXG prefetch page and, therefore should be ignored3. The third request is the actual prefetching request of your website. Let’s click on it to see the details:
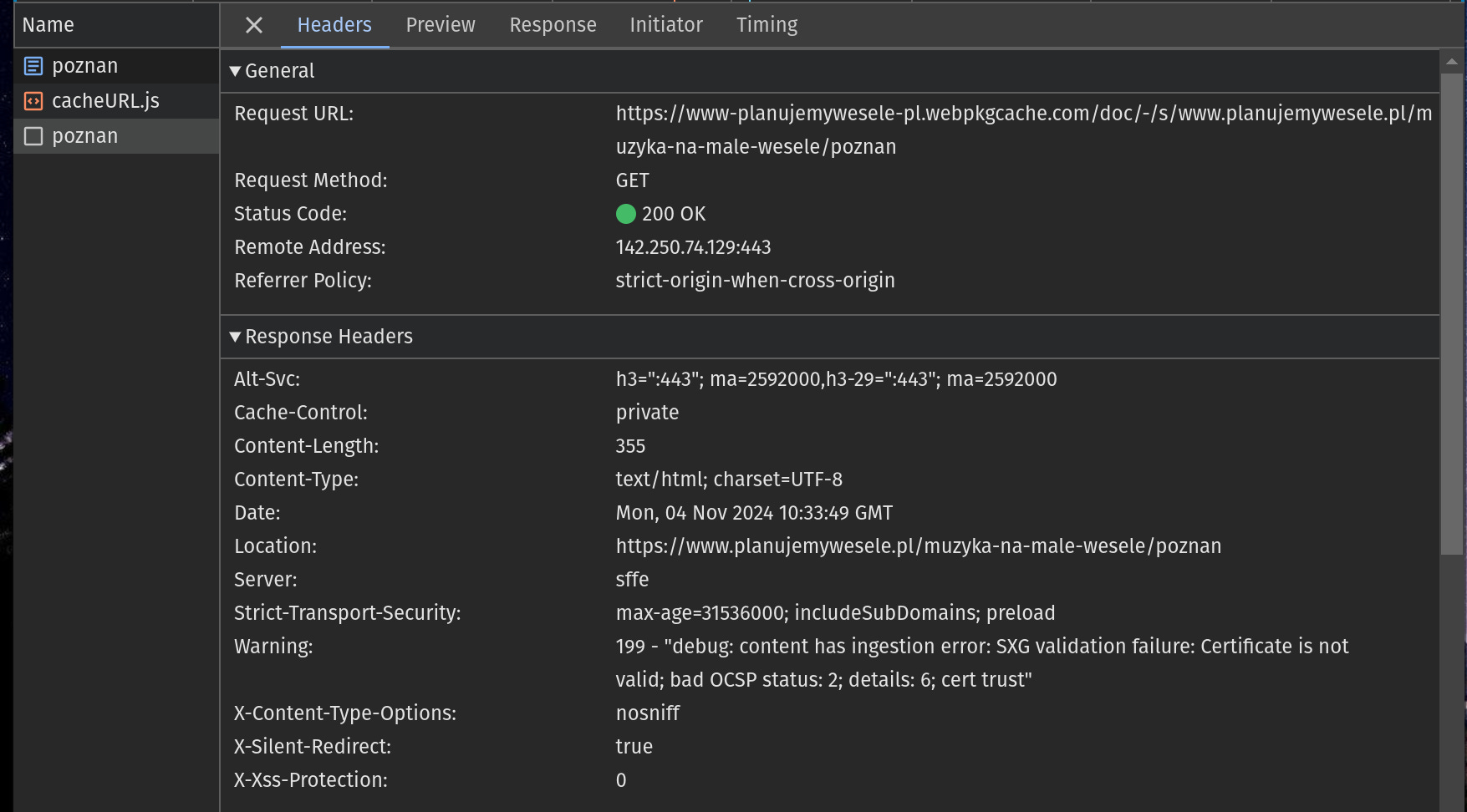
The important parts are:
The request URL points to a special URL within the webpkgcache.com domain. It is the domain of Google SXG cache. The cache URL is constructed by transforming the original URL4.
The presence of a Location header is one of Google SXG's methods for signaling that an entry is not yet cached. The value of this header contains the URL of the original page (non-SXG version). It’s like Google SXG cache is saying: “I don’t have the SXG version yet, but in case you need the page right now, please request the original version as a fallback.“
Fallback mechanism
Unfortunately, Chrome Dev Tools doesn’t allow you to see the response body if the URL is absent from the SXG cache. The Preview and Response tabs contain only the following error message (which may be related to this issue):
Failed to load response data: No data found for resource with given identifierHowever, you can see it with curl. Just point it to the Google SXG cache URL and set the proper Accept header:
curl -H "Accept: application/signed-exchange;v=b3" https://www-planujemywesele-pl.webpkgcache.com/doc/-/s/www.planujemywesele.pl/muzyka-na-male-wesele/poznanAssuming the page is not yet present in the Google SXG cache, you will get:
<HTML><HEAD> <meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>Redirecting</TITLE> <META HTTP-EQUIV="refresh" content="0; url=https://www.planujemywesele.pl/muzyka-na-male-wesele/poznan"> </HEAD> <BODY onLoad="location.replace('https://www.planujemywesele.pl/muzyka-na-male-wesele/poznan'+document.location.hash)">This simple HTML page aims to redirect the user to the original website. This is a fallback mechanism Google uses to ensure users can access the site, even if it's not yet in the SXG cache.
The fallback mechanism has interesting property. It uses client-side redirection that alters referrer.
Typically when someone comes from Google, the referrer should be set to www.google.com or one of Google’s regional domains. But in case the SXG fallback mechanism, you will see visitors coming from your-domain-com.webpkgcache.com.
You should keep that in mind when using your web analytics.
Ingestion errors
If you looked closely, you might have seen a Warning header.
Google SXG cache uses this header to communicate errors that happen during ingestion. If you wonder how the SXG Validator browser extension knows the cache error message, it gets it from the value of this header.
In our example, we got the following error message:
199 - "debug: content has ingestion error: SXG validation failure: Certificate is not valid; bad OCSP status: 2; details: 6; cert trust"This is a classic example of transient error, at least if you use Cloudflare. It will vanish when you repeat the request a few seconds later.
You may observe other errors. Most of them could be eliminated by meeting all the requirements described in the previous parts.
Note that fixing the error won’t be reflected immediately in the Warning header, as caching is involved. Try with different URL to get feedback earlier.
If you don’t see the Warning header, it means Google needs more time to fetch the page and store it in the SXG cache.
The actual SXG response
By submitting the URL on the SXG prefetch page, we requested the SXG version of the document from the Google SXG cache. It automatically activated the cache population mechanism, ultimately retrieving the page and storing it in the cache.
Now, let’s clear the requests in Chrome Dev Tools and submit the same URL as previously. This time, the result looks different:
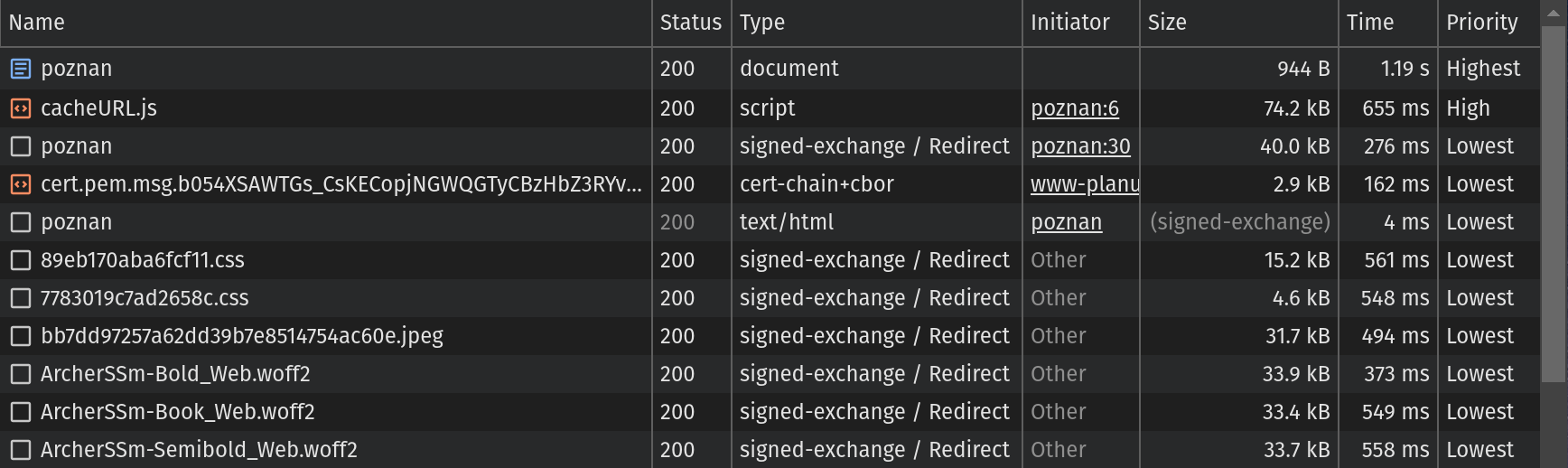
You may notice there are a lot of HTTP responses. We will get to them, but let’s move from the top as previously. Ignore the first 2 responses like before and focus on the third one.
In the Type column, you can see “signed-exchange / Redirect” instead of the “text/html” you saw earlier. When you click on the third row, you will see details:

This time you won’t see the Location header and the Content-Type header is set to application/signed-exchange;v=b3 (previously it was set to text/html; charset=UTF-8). Those things tell you the SXG of the main document has been correctly generated and stored in the Google SXG cache.
If your document uses subresources, the Link header will include URLs of copies stored in the Google SXG cache.
If the list doesn’t include one or more of your subresources, or it there is no Link header at all it means Cloudflare couldn’t include some or all of your subresources. Most probably it is caused by hosting subresources on a different (sub)domain. The other cause is if you have more than 20 subresources—you will miss anything beyond that limit. See the previous part for details.
Notice the structure of URLs in the Link header:
https://domain-com.webpkgcache.com/sub/XXX/s/domain.com/path/file.jpgSame as with HTML pages, they point to the webpkgcache.com domain. However, the path is constructed differently. The most important difference is the presence of the first few characters of the integrity hash of the subresource (marked with XXX above). This way, the location of a subresource is closely linked to its content.
When you open the Preview tab you will see the decoded SXG response:
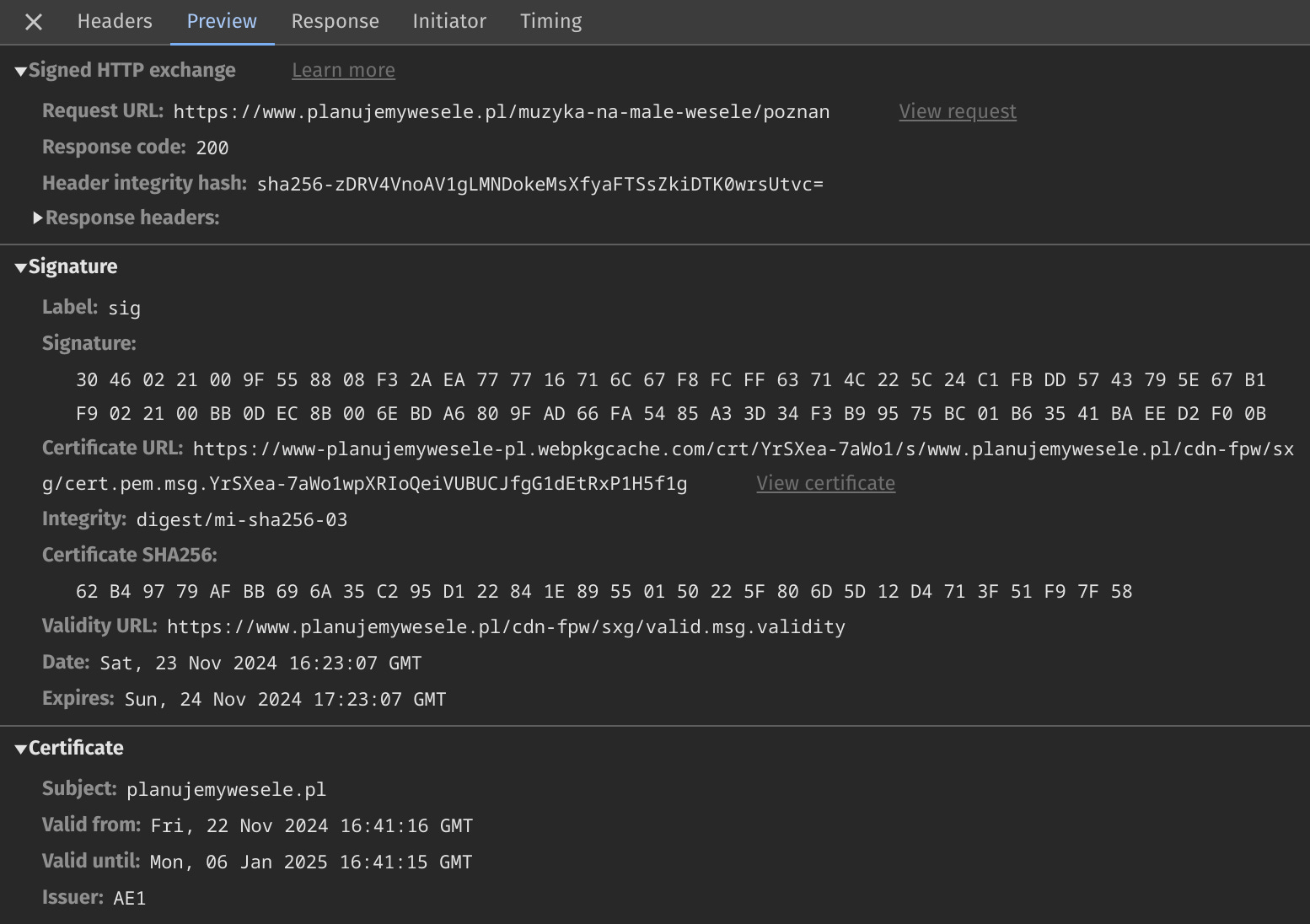
The most useful fields are:
Signature Date. It tells you when the SXG was generated. Remember that the time you see there has to be adjusted by adding 1 hour5. From the debugging perspective, it will tell you if the SXG is fresh or not.
Response headers. This section lists all the HTTP headers (along with values) included in the SXG when they were generated by Cloudflare Automated Signed Exchanges (ASX). Headers are critical for prefetching subresources; you will understand why after reading the next part of the series.
SXG subresource response
The remaining requests of type “signed-exchange / Redirect” are related to SXG subresources. When you examine them, they will look similar. The most important differences in the Preview tab are:
Content type (in Response headers field). Your main document is likely HTML, while subresources are styles, images, etc. This header will reflect that.
Signature Date and Signature Expires. Each subresource has independent signature dates and typically should have higher expiration times than the main document.
Apart from that, you won’t find a Link header in the HTTP response. That’s because subresource nesting is not allowed: subresources can’t have sub-subresources.
Every HTTP response for an existing entry you get from the SXG cache has a Content-Type header set to “application/signed-exchange;v=b3”. The actual content type of the subresource is encoded in the body of the response. It can be examined in the Preview tab.
I like to think of SXG as a package containing the complete HTTP response. This package must be delivered to the browser through a separate HTTP response.
CORS errors
Now, that you are equipped with the debug tool and understand how to use it, let’s examine the most common error you will encounter when you inspect network requests in Chrome Dev Tools:

If you switch to console view, you may see:
⨂ Access to link prefetch resource at 'https://www-yourdomain-com.webpkgcache.com/sub/d3_L0zvunVqT/s/www.yourdomain.com/file.jpeg' from origin 'https://www.google.com' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. ⨂ GET https://www-yourdomain-com.webpkgcache.com/sub/d3_L0zvunVqT/s/www.yourdomain.com/file.jpeg net::ERR_FAILED 200 (OK)Why do those errors occur?
When I first encountered this error I was confused.
CORS (Cross-Origin Resource Sharing) errors typically occur when performing cross-origin requests with invalid or missing CORS policy. However, the subresources are stored in the Google SXG cache and only Google has control over its CORS policy. Is it possible Google set an invalid CORS policy on its own website?
Let’s examine the problematic request:
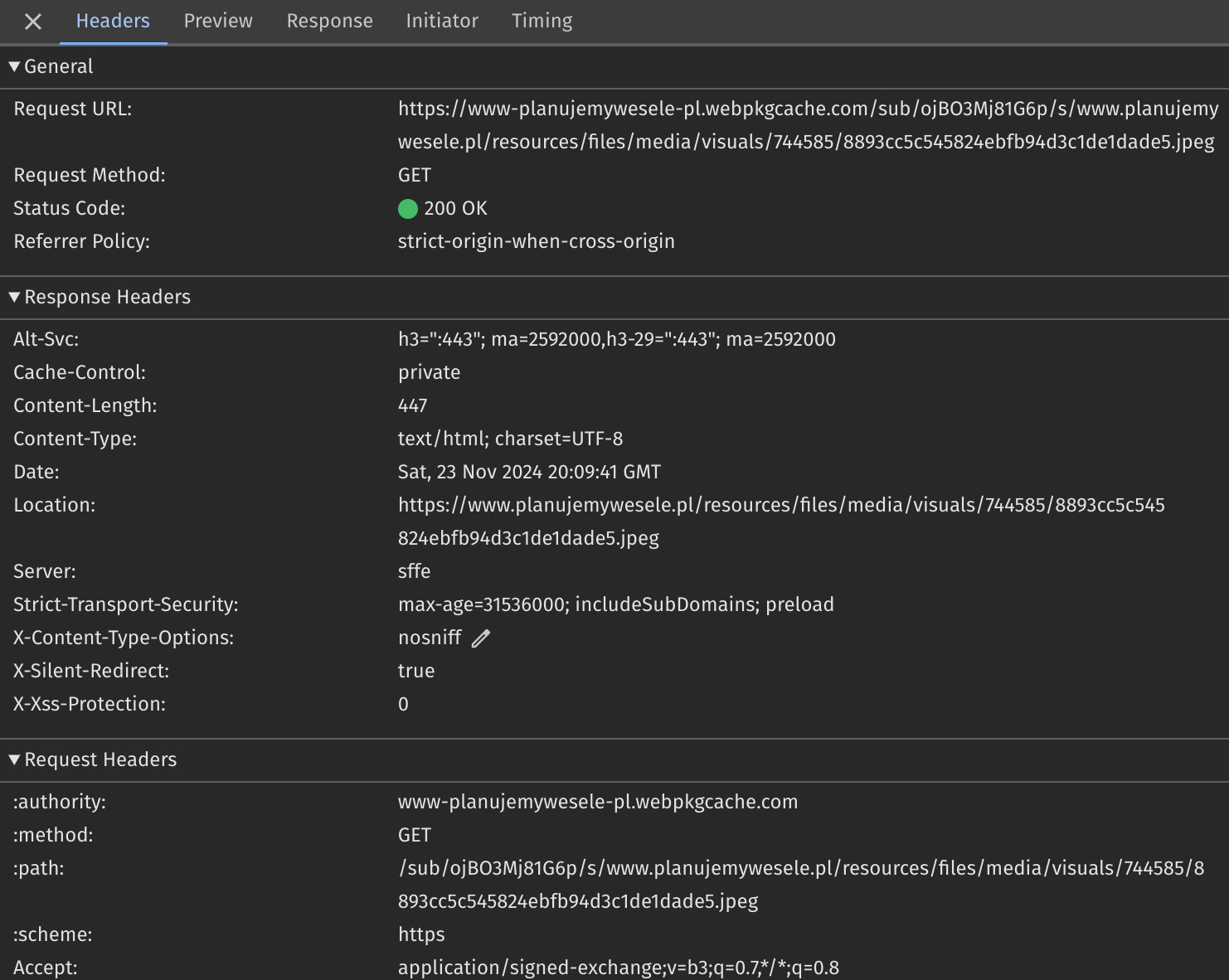
There are no CORS headers in the response. In contrast, when examining valid response, the Access-Control-Allow-Origin header is clearly there:
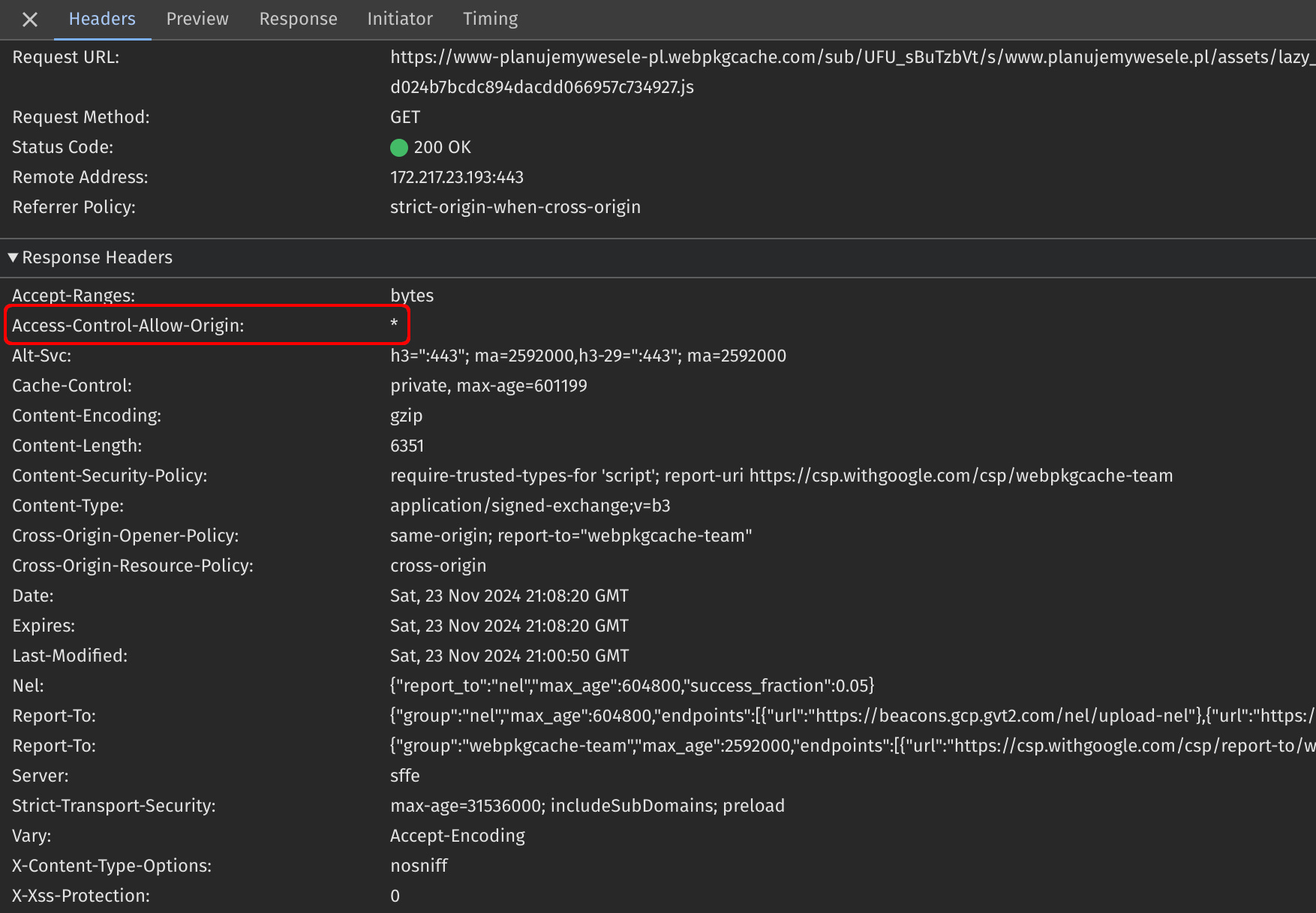
So this is the reason for the error. But…
Why is the CORS policy different for this particular file?
When you compare the error with a valid response again, you will notice other differences. The most critical HTTP headers that differ in the invalid response include:
Content-Type. It’s set to “text/html; charset=UTF-8”. But it is supposed to be an SXG-wrapped image…
Location. It is set to the actual image location on the origin server.
Also, when navigating to the Preview tab this error message shows up:
Failed to load response data: No data found for resource with given identifierSeems familiar… Wait. It’s the fallback mechanism Google SXG cache uses when asked for non-existent SXGs of HTML documents! It appears Google reuses it for subresources too. As those responses don’t contain CORS headers, CORS errors occur.
So, if you ask Google SXG cache for a non-existing image (or any other file type), instead of this image (or file) you'll receive an HTML response. The HTTP response code is 200, but don't let that fool you. In reality:
When prefetching, a CORS error means a given (sub)resource is missing from the Google SXG cache.

Try it yourself
If you want to experience the errors, try a demo page that contains two subresources—one that successfully prefetches and another that fails to prefetch.
Go to the SXG prefetching page and paste the following URL. Remember to change the NUMBER to a random number between 1 and 10000:
https://www.planujemywesele.pl/sxg-tests/good-bad-subresource/NUMBERAfter providing the URL, start repeatedly hitting the Submit button.
Watch the process unfold:
First, you'll need to wait for the Google SXG cache to cache the page.
Then wait a few more seconds while the Google SXG cache downloads the subresources. CORS errors will appear for both subresources.
After this process completes, you'll observe that one of the subresources successfully prefetches (good.css) while the other still fails with a CORS error (bad.css).
Google search behavior
The same CORS error occurs when the Google SXG cache lacks a copy of the main document for a specific page. Such errors may occur in actual Google search results, as demonstrated below:
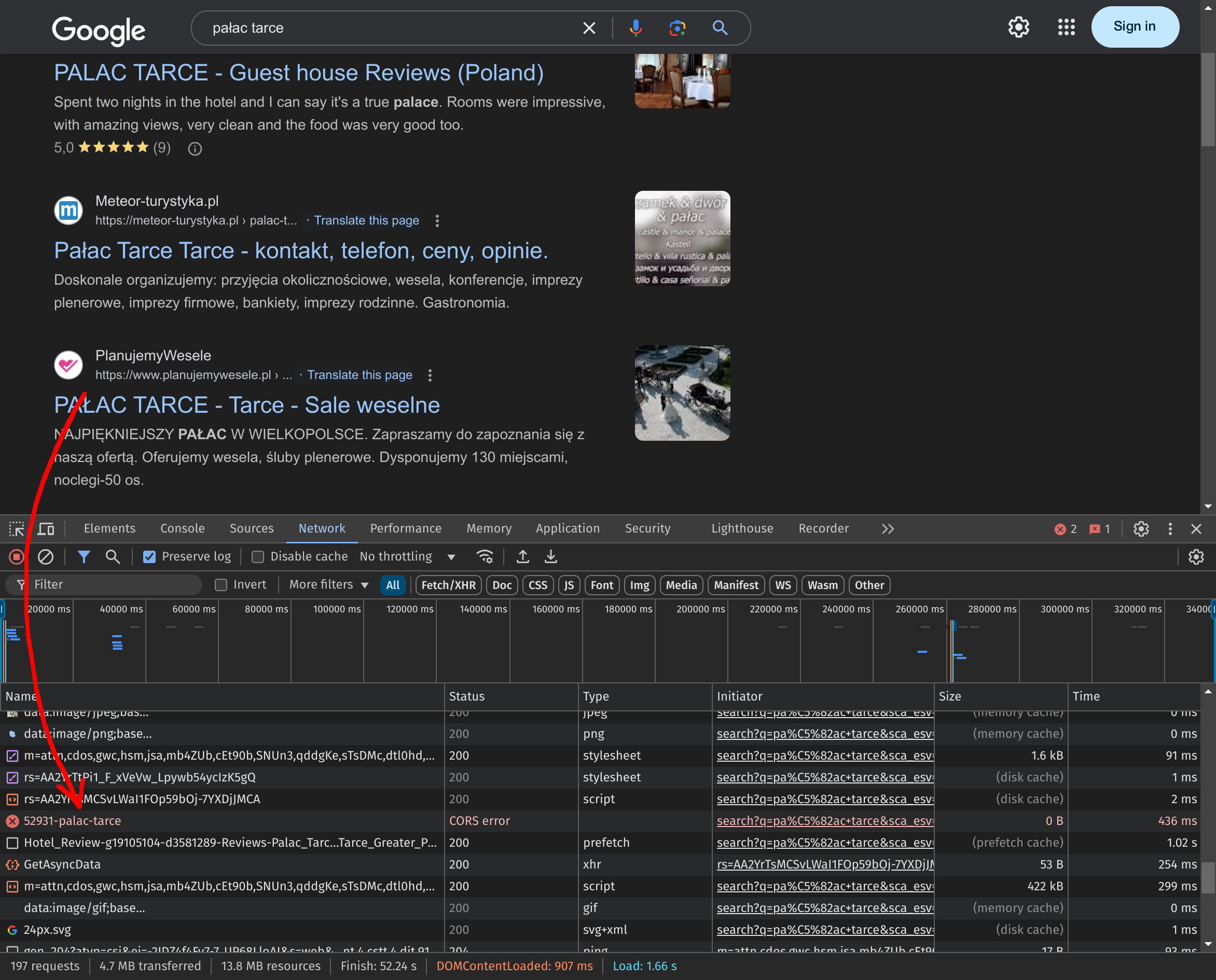
The SXG prefetch page used for debugging employs different mechanics to invoke prefetching, so the CORS error message won't be displayed there. However, when using this tool, you can still see the warnings described in the Ingestion errors section. Therefore, the SXG prefetch page should suffice in debugging and fixing errors in the main SXG document.
Other errors
Sometimes you may observe an error similar to the following:

In the Status column you can see:
(failed) net::ERR_INVALID_SIGNED_EXCHANGEWhen you inspect the request details and open the Preview tab, you may see something like this:
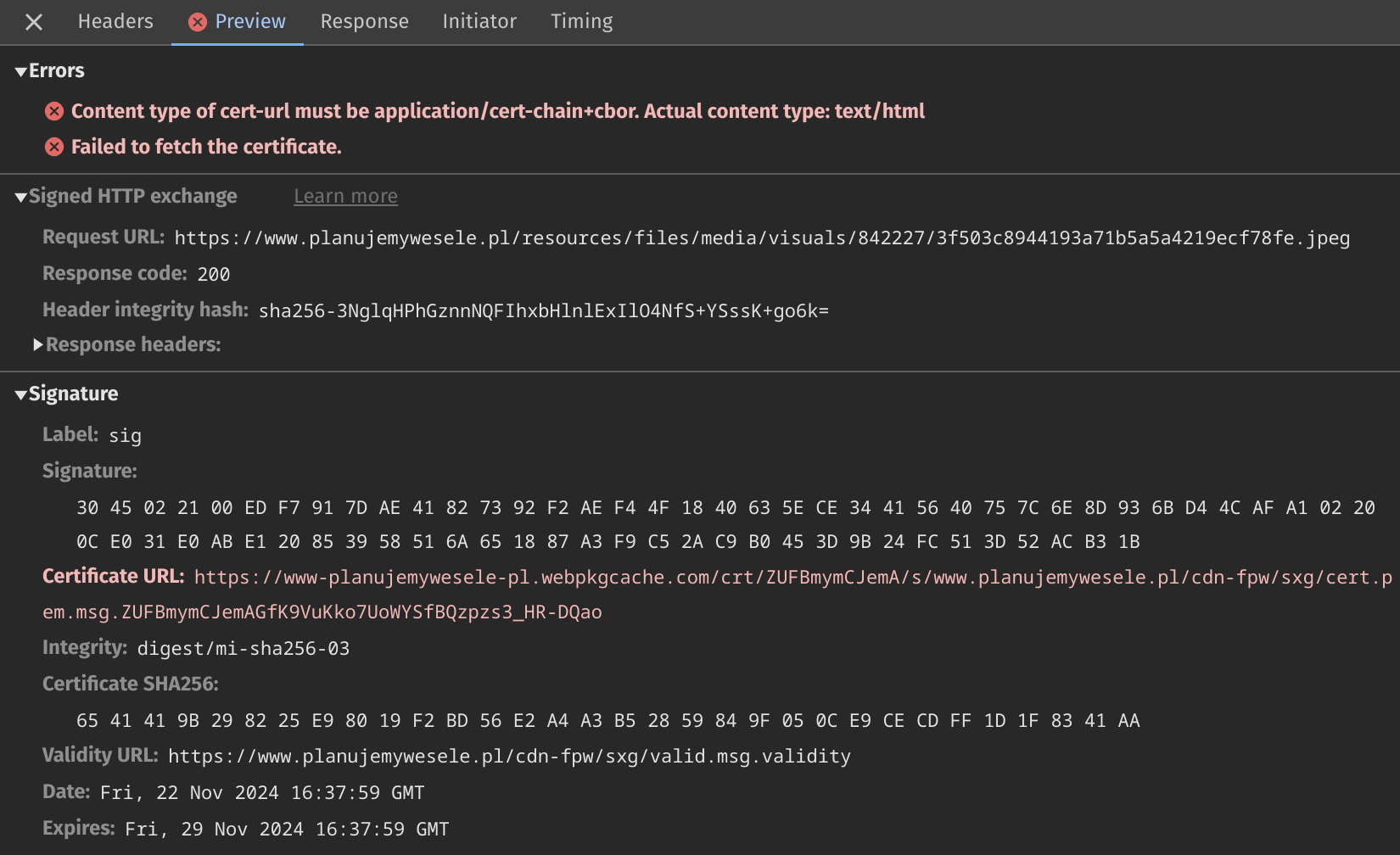
The error message says:
Content type of cert-url must be application/cert-chain+cbor. Actual content type: text/html Failed to fetch the certificate.Also, you may notice the Signature→Certificate URL field is marked in red.
In this case, the signed exchange is invalid because the certificate is inaccessible. The browser tried to download it but received an HTML page instead. You probably already know what this means. Yes, this HTML page is the fallback page served by Google SXG cache when the file is missing. It seems Google uses it for missing certificates too6.
Conclusion
Now you can diagnose SXG errors and know that most of them are caused by missing entries in the Google SXG cache.
But why are subresources sometimes not present in the SXG cache?
How does Google decide which subresources to cache and which not?
Most importantly: how do you convince Google to perform the caching of all subresources used by the page?
I will explain it in the next parts of the series:

Thank you for reading!
The remaining 1% of the performance benefits is the main HTML document, which is still prefetched.
This is a theoretical value selected to better illustrate the point. As far as I know, the SXG spec doesn’t restrict the number of subresources. However, implementations do: currently Cloudflare ASX and Google SXG-cache limit it to 20, as mentioned in the previous post.
Alternatively, you can filter them out by entering the “webpkgcache“ string in the filter field. I try to avoid that because unless I remove it, it will stay. Later, I forget about it and wonder why I don’t see requests I expect. That may be frustrating.
The algorithm for computing the subdomain and the URL path suffix is the same as for the AMP Cache, while the infix string /doc/-/ is different.
I’m not sure why the signature time is 1 hour before the actual time it was generated. It may be a safeguard against a clock of the server generating signature not being in perfect sync with the clock on the client validating it.
Without this safeguard, if the server generated a signature at 10:00 and the client believes the current time is 9:59, it may reject the signature as invalid because—from the client’s perspective—the signature will start being valid in 1 minute.
This won’t be an issue for most users, but when the client is Googlebot, and the server is Cloudflare it may happen regularly.
In my experience, a missing certificate is a temporary error that typically lasts for a few minutes at most.